
Regularizing Action Policies for Smooth Control with Reinforcement Learning
Abstract
A critical problem with the practical utility of controllers trained with deep Reinforcement Learning (RL) is the notable lack of smoothness in the actions learned by the RL policies. This trend often presents itself in the form of control signal oscillation and can result in poor control, high power consumption, and undue system wear. We introduce Conditioning for Action Policy Smoothness (CAPS), a simple but effective regularization on action policies, which offers consistent improvement in the smoothness of the learned state-to-action mappings of neural network controllers, reflected in the elimination of high-frequency components in the control signal. Tested on a real system, improvements in controller smoothness on a quadrotor drone resulted in an almost 80% reduction in power consumption while consistently training flight-worthy controllers.
This work has been accepted for publication and is set to appear at the International Conference on Robotics and Automation (ICRA) 2021.
Main Results
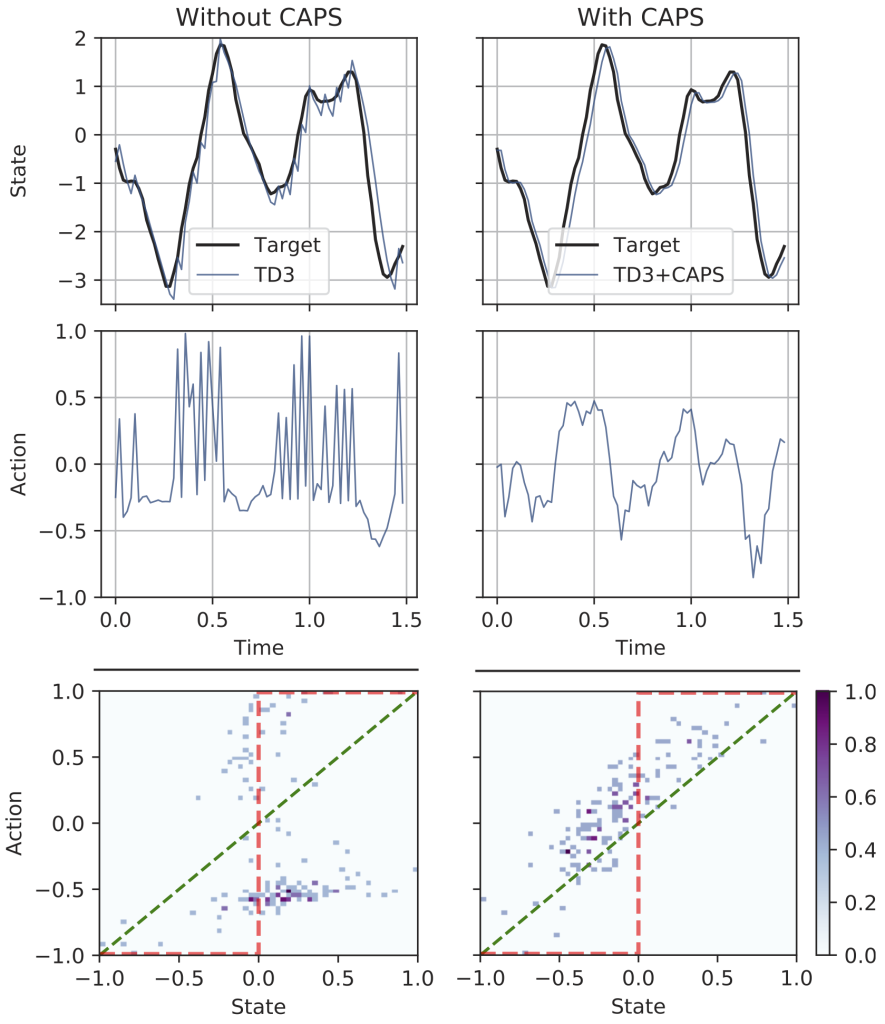
We noticed that even on simple toy problems deep-RL algorithms failed to produce smooth outputs. So we introduced our regularization method “CAPS” and tested it on OpenAI Gym benchmarks, where CAPS produced smoother responses on all tested environments. The benefits of CAPS are also visually noticeable in some tasks, as shown by the example of the pendulum task below. Additional results are provided in our paper and in the supplementary material.


To test real-world performance on hardware, we also tested CAPS on a high-performance quadrotor drone, the schematics and training for which were based on Neuroflight. CAPS agents allowed for training with simpler rewards and still achieves comprable tracking performance while offering over 80% reduction in power consumption and over 90% improvement in smoothness (more details in our paper).

We then took a Fourier transform of motor outputs during actual flights and plotted them to show how CAPS compares to Neuroflight and a tuned PID controller with filtered inputs:
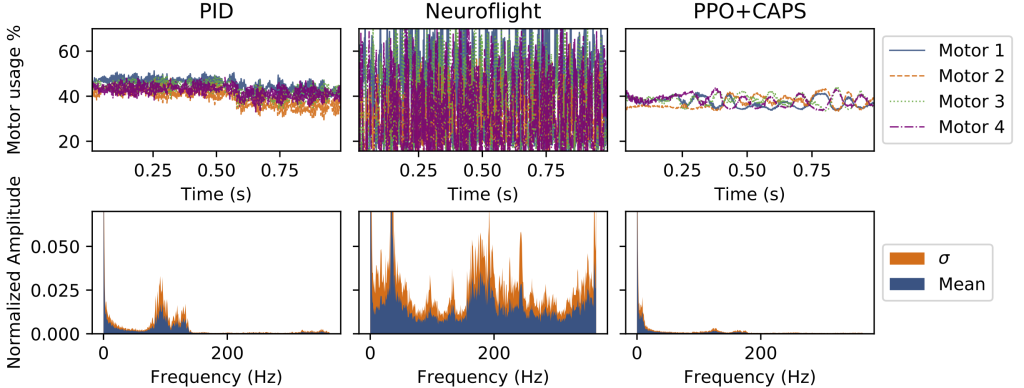
In short, our method allowed for very significant gains in motor actuation smoothness, leading to agents drawing, on average, 4.86±2.32 amps during flight tests, while the Neuroflight agents drew an average of 22.87 amps on similar tests. PID meanwhile took an average of 8.07 amps.
Method
We added 2 regularization techniques to the standard optimization of Deep-RL algorithms.
Temporal Smoothness
To ensure that subsequent actions are similar to current actions we introduce the following criterion (\(D\) being a distance metric relating actions):
| $$L_T = D(\pi(s_t), \pi(s_{t+1}))$$ |
Spatial Smoothness
To ensure that similar states map to similar actions we introduce the following criterion:
| $$L_S = D(\pi(s), \pi(\bar{s}))$$ where \(\bar{s} \sim \phi(s)\) is drawn from a distribution around \(s\) |
Full optimization criterion
For a policy optimization criteria, \(J_\pi\), on policy \(\pi\), the CAPS regularizations are introduced as weighted losses:
| $$J_\pi^\text{CAPS} = J_\pi – \lambda_T L_T – \lambda_S L_S$$ |
In practice, we use euclidean distance measures, i.e. \(D(a_1,a_2) = ||a_1 – a_2||_2\) and a normal distribution \(\phi(s) = N(s,\sigma)\) where \(\phi\) is set based on expected measurement noise and/or tolerance.
Code
Reference
If you find our work useful, please consider citing:
@inproceedings{caps2021,
title={Regularizing Action Policies for Smooth Control with Reinforcement Learning},
author={Siddharth Mysore* and Bassel Mabsout* and Renato Mancuso and Kate Saenko},
journal={IEEE International Conference on Robotics and Automation},
year={2021},
}