About
This project is a continuation of the “Near-Data Data Transformation” project that was funded by the RedHat Collaboratory in the previous cycle.
The outcome of the previous project was the prototyping of an FGPA-based custom hardware design that is able to transform the data layout on the fly allowing the application to access arbitrary subsets of data stored in memory, called Relational Memory. In this work, we propose to integrate our Relational Memory prototype with a DDR4 memory controller, which we are developing in-house.
In order to achieve this, we will further develop the simulation infrastructure, adjust the communication protocols of our prototype, exploit the direct access of memory to ensure better performance, and extend the RISC-V ISA for ease of use. Lastly, in a parallel track, we propose to integrate Relational Memory into a database system in preparation for our ultimate vision of vertical integration of the application and the memory controller.
Project Information
One of the key bottlenecks in data-intensive applications is moving data through the memory hierarchy to processing elements, like CPUs and accelerators. The performance and predictability challenges are particularly significant for systems where tail latency is important, like cloud-based applications, computing on the edge, and other applications that follow service-level agreements (SLAs). This is exacerbated for applications with a large memory footprint that exhibit complex memory access patterns.To address these challenges, multi-level caches are used to hide the latency of memory accesses, which are particularly effective when data accesses exhibit spatial and temporal locality.
However, several data-intensive applications do not always exhibit such spatiotemporal locality. Consider a data management workload that consists of analytical queries over different quantities and transactional queries that update or access individual records. Such a hybrid transactional/analytical processing (HTAP) use-case will have queries over the same relational tables that target different sets of rows and columns, and hence despite being on the same overall data collection, the queries will have very different access patterns. Such applications motivate our overarching research, which attempts to answer the question:
Can we build hardware that will allow the applications to operate with spatiotemporal data locality without the need to fully re-engineer them?
This question fueled our prior work on “Near-Data Data Transformation” Controller which has been funded by the BU-RedHat Collaboratory for 2022 [1, 2, 8] and led to the development of
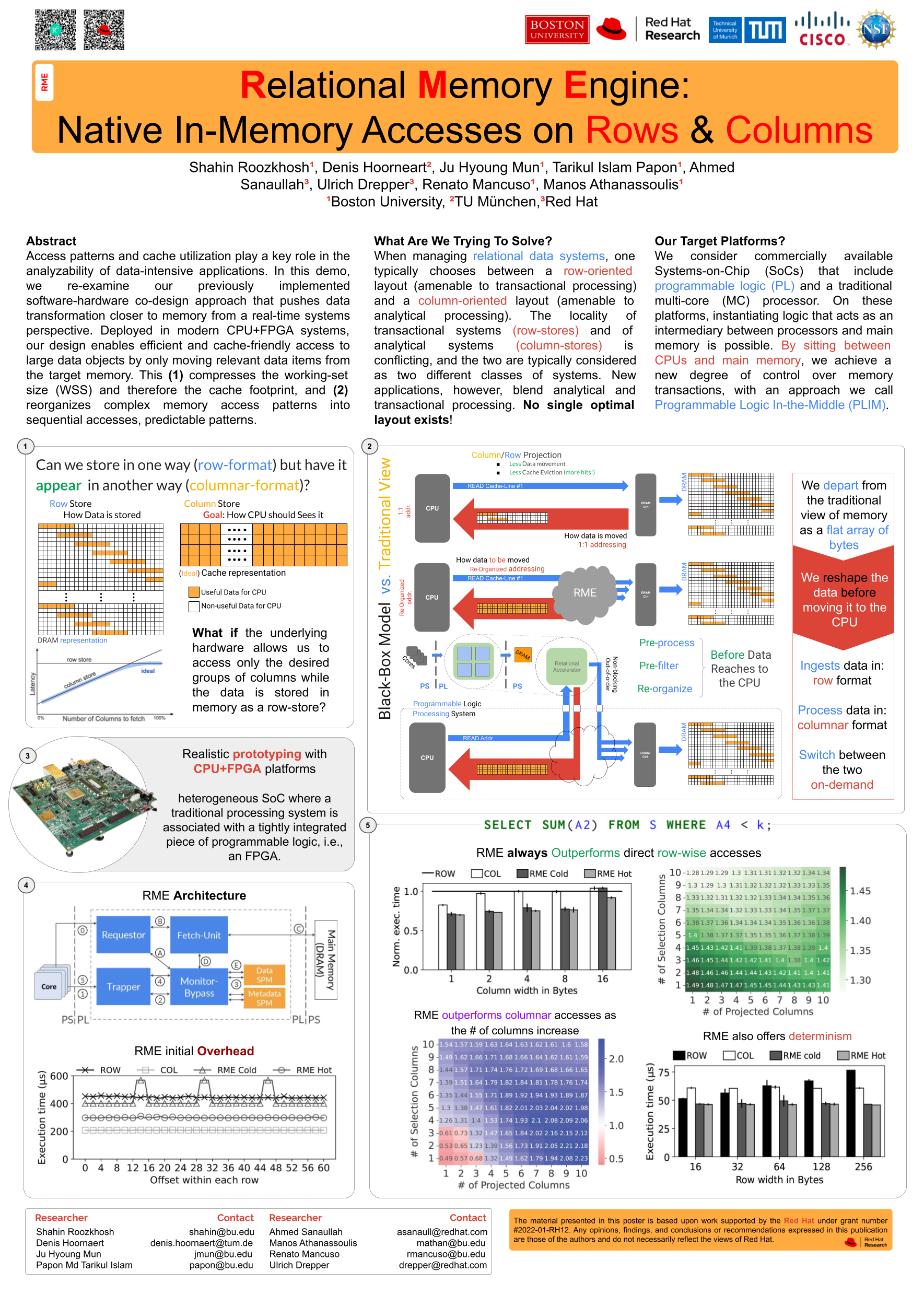
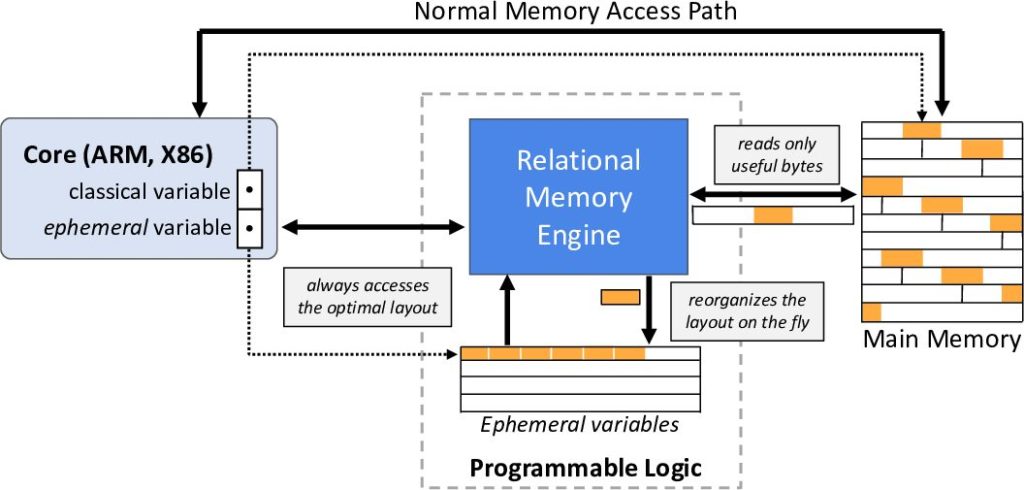
Relational Memory [9, 10], an FPGA-based hardware-based data transformation engine that sits between the processor and the memory and converts data layouts on-the-fly, from a row-oriented layout to any group of columns.
In this project, motivated by our first successful results, we want to answer the questions: Can we integrate our data transformation hardware in a memory controller so that any system is able to benefit from it? and What does it take to fully integrate our transformation hardware in production-ready database systems, and how their software architecture might be affected? The infrastructure needed to propose a new memory controller, the degree of performance optimization required, and the re-engineering of data systems to use this hardware are the defining challenges of this proposal. Overall, in this proposal, we aim to integrate our data transformation hardware downstream within a DDR memory controller, and upstream with an open-source DBMS. The research in this proposal will be conducted in parallel by the same team and is interconnected with the research of the proposal “Toward On-the-fly Reorganization of High-order Data Objects” which has also been submitted for consideration to the same call.
Relational Memory Controller: Research and Technical Challenges.
First, building new memory controller hardware is typically an expensive and lengthy (multiple-years) process that is driven mostly by industry vendors. To address this challenge, our RedHat partners have provided an in-house FPGA-based implementation of a DDR3 memory controller, which is the starting basis of this project. The first goal is to upgrade this implementation to be able to capture the capabilities of a DDR4 memory controller, a task that is already underway. Next, we will fine-tune the DDR4 FPGA-based implementation of the memory controller, optimize its performance, and validate its operation on real hardware. Once this step is completed, we will proceed with the crux of the proposal, which is the integration of our Relational Memory prototype with the DDR4 memory controller. During this integration, we expect a part of our effort to be devoted to using the simpler communication channels of the controller (when compared with the AXI protocol used in our original prototype), while we also anticipate that we can achieve better performance and utilization results now that we can integrate tightly with memory. For example, we can use features of the memory controller that allow for accesses without having always to recreate a cache line. Further, to ensure ease of use of the newly proposed RMC, we propose to extend the RISC-V ISA in order to directly use it. That way, RMC will be able to quickly integrate with systems with minimal re-engineering effort. Note that while our goal is to build a new memory controller, its impact can be profound even without being printed in ASIC. Specifically, the proposed design will significantly benefit data management on the edge with FPGA-based soft-cores. At the same time, we will devote a parallel track of our efforts in integrating relational memory with a full-blown open-source database system to fully showcase its benefits and to act as preparation for the ultimate goal of integrating our RMC with a full-blown database system.
Relational Memory Engine
RME comprises of four modules: 1) the Requestor orchestrates accesses to main memory, 2) the Fetch Unit retrieves data from main memory, 3) the Monitor Bypass monitors the completion and availability of each reorganized data, and 4) the Trapper provides the interface between RME and the CPUs.
Presentations, Talks and Posters
Poster